(Quick Reference)
5 Configuration - Reference Documentation
Authors: Graeme Rocher, Peter Ledbrook, Marc Palmer, Jeff Brown, Luke Daley, Burt Beckwith, Lari Hotari
Version: 2.5.3
5 Configuration
It may seem odd that in a framework that embraces "convention-over-configuration" that we tackle this topic now. With Grails' default settings you can actually develop an application without doing any configuration whatsoever, as the quick start demonstrates, but it's important to learn where and how to override the conventions when you need to. Later sections of the user guide will mention what configuration settings you can use, but not how to set them. The assumption is that you have at least read the first section of this chapter!
5.1 Basic Configuration
For general configuration Grails provides two files:
grails-app/conf/BuildConfig.groovygrails-app/conf/Config.groovy
Both of them use Groovy's
ConfigSlurper syntax. The first,
BuildConfig.groovy, is for settings that are used when running Grails commands, such as
compile,
doc, etc. The second file,
Config.groovy, is for settings that are used when your application is running. This means that
Config.groovy is packaged with your application, but
BuildConfig.groovy is not. Don't worry if you're not clear on the distinction: the guide will tell you which file to put a particular setting in.
The most basic syntax is similar to that of Java properties files with dot notation on the left-hand side:
Note that the value is a Groovy string literal! Those quotes around 'world' are important. In fact, this highlights one of the advantages of the ConfigSlurper syntax over properties files: the property values can be any valid Groovy type, such as strings, integers, or arbitrary objects!
Things become more interesting when you have multiple settings with the same base. For example, you could have the two settings
foo.bar.hello = "world"
foo.bar.good = "bye"
both of which have the same base:
foo.bar. The above syntax works but it's quite repetitive and verbose. You can remove some of that verbosity by nesting properties at the dots:
foo {
bar {
hello = "world"
good = "bye"
}
}or by only partially nesting them:
foo {
bar.hello = "world"
bar.good = "bye"
}However, you can't nest after using the dot notation. In other words, this
won't work:
// Won't work!
foo.bar {
hello = "world"
good = "bye"
}Within both
BuildConfig.groovy and
Config.groovy you can access several implicit variables from configuration values:
| Variable | Description |
|---|
| userHome | Location of the home directory for the account that is running the Grails application. |
| grailsHome | Location of the directory where you installed Grails. If the GRAILS_HOME environment variable is set, it is used. |
| appName | The application name as it appears in application.properties. |
| appVersion | The application version as it appears in application.properties. |
For example:
my.tmp.dir = "${userHome}/.grails/tmp"In addition,
BuildConfig.groovy has
| Variable | Description |
|---|
| grailsVersion | The version of Grails used to build the project. |
| grailsSettings | An object containing various build related settings, such as baseDir. It's of type BuildSettings. |
and
Config.groovy has
Those are the basics of adding settings to the configuration file, but how do you access those settings from your own application? That depends on which config you want to read.
The settings in
BuildConfig.groovy are only available from
command scripts and can be accessed via the
grailsSettings.config property like so:
target(default: "Example command") {
def maxIterations = grailsSettings.config.myapp.iterations.max
…
}If you want to read runtime configuration settings, i.e. those defined in
Config.groovy, use the
grailsApplication object, which is available as a variable in controllers and tag libraries:
class MyController {
def hello() {
def recipient = grailsApplication.config.foo.bar.hello render "Hello ${recipient}"
}
}and can be easily injected into services and other Grails artifacts:
class MyService {
def grailsApplication String greeting() {
def recipient = grailsApplication.config.foo.bar.hello
return "Hello ${recipient}"
}
}As you can see, when accessing configuration settings you use the same dot notation as when you define them.
5.1.1 Built in options
Grails has a set of core settings that are worth knowing about. Their defaults are suitable for most projects, but it's important to understand what they do because you may need one or more of them later.
Build settings
Let's start with some important build settings. Although Grails requires JDK 6 when developing your applications, it is possible to deploy those applications to JDK 5 containers. Simply set the following in
BuildConfig.groovy:
grails.project.source.level = "1.5"
grails.project.target.level = "1.5"
Note that source and target levels are different to the standard public version of JDKs, so JDK 5 -> 1.5, JDK 6 -> 1.6, and JDK 7 -> 1.7.
In addition, Grails supports Servlet versions 2.5 and above but defaults to 2.5. If you wish to use newer features of the Servlet API (such as 3.0 async support) you should configure the
grails.servlet.version setting appropriately:
grails.servlet.version = "3.0"
Runtime settings
On the runtime front, i.e.
Config.groovy, there are quite a few more core settings:
grails.config.locations - The location of properties files or addition Grails Config files that should be merged with main configuration. See the section on externalised config.grails.enable.native2ascii - Set this to false if you do not require native2ascii conversion of Grails i18n properties files (default: true).grails.views.default.codec - Sets the default encoding regime for GSPs - can be one of 'none', 'html', or 'base64' (default: 'none'). To reduce risk of XSS attacks, set this to 'html'.grails.views.gsp.encoding - The file encoding used for GSP source files (default: 'utf-8').grails.mime.file.extensions - Whether to use the file extension to dictate the mime type in Content Negotiation (default: true).grails.mime.types - A map of supported mime types used for Content Negotiation.grails.serverURL - A string specifying the server URL portion of absolute links, including server name e.g. grails.serverURL="http://my.yourportal.com". See createLink. Also used by redirects.grails.views.gsp.sitemesh.preprocess - Determines whether SiteMesh preprocessing happens. Disabling this slows down page rendering, but if you need SiteMesh to parse the generated HTML from a GSP view then disabling it is the right option. Don't worry if you don't understand this advanced property: leave it set to true.grails.reload.excludes and grails.reload.includes - Configuring these directives determines the reload behavior for project specific source files. Each directive takes a list of strings that are the class names for project source files that should be excluded from reloading behavior or included accordingly when running the application in development with the run-app command. If the grails.reload.includes directive is configured, then only the classes in that list will be reloaded.
War generation
grails.project.war.file - Sets the name and location of the WAR file generated by the war commandgrails.war.dependencies - A closure containing Ant builder syntax or a list of JAR filenames. Lets you customise what libraries are included in the WAR file.grails.war.copyToWebApp - A closure containing Ant builder syntax that is legal inside an Ant copy, for example "fileset()". Lets you control what gets included in the WAR file from the "web-app" directory.grails.war.resources - A closure containing Ant builder syntax. Allows the application to do any other work before building the final WAR file
For more information on using these options, see the section on
deployment
5.1.2 Logging
The Basics
Grails uses its common configuration mechanism to provide the settings for the underlying
Log4j log system, so all you have to do is add a
log4j setting to the file
grails-app/conf/Config.groovy.
So what does this
log4j setting look like? Here's a basic example:
log4j = {
error 'org.codehaus.groovy.grails.web.servlet', // controllers
'org.codehaus.groovy.grails.web.pages' // GSP warn 'org.apache.catalina'
}This says that for loggers whose name starts with 'org.codehaus.groovy.grails.web.servlet' or 'org.codehaus.groovy.grails.web.pages', only messages logged at 'error' level and above will be shown. Loggers with names starting with 'org.apache.catalina' logger only show messages at the 'warn' level and above. What does that mean? First of all, you have to understand how levels work.
Logging levels
There are several standard logging levels, which are listed here in order of descending priority:
- off
- fatal
- error
- warn
- info
- debug
- trace
- all
When you log a message, you implicitly give that message a level. For example, the method
log.error(msg) will log a message at the 'error' level. Likewise,
log.debug(msg) will log it at 'debug'. Each of the above levels apart from 'off' and 'all' have a corresponding log method of the same name.
The logging system uses that
message level combined with the configuration for the logger (see next section) to determine whether the message gets written out. For example, if you have an 'org.example.domain' logger configured like so:
warn 'org.example.domain'
then messages with a level of 'warn', 'error', or 'fatal' will be written out. Messages at other levels will be ignored.
Before we go on to loggers, a quick note about those 'off' and 'all' levels. These are special in that they can only be used in the configuration; you can't log messages at these levels. So if you configure a logger with a level of 'off', then no messages will be written out. A level of 'all' means that you will see all messages. Simple.
Loggers
Loggers are fundamental to the logging system, but they are a source of some confusion. For a start, what are they? Are they shared? How do you configure them?
A logger is the object you log messages to, so in the call
log.debug(msg),
log is a logger instance (of type
Log). These loggers are cached and uniquely identified by name, so if two separate classes use loggers with the same name, those loggers are actually the same instance.
There are two main ways to get hold of a logger:
- use the
log instance injected into artifacts such as domain classes, controllers and services;
- use the Commons Logging API directly.
If you use the dynamic
log property, then the name of the logger is 'grails.app.<type>.<className>', where
type is the type of the artifact, for example 'controllers' or 'services', and
className is the fully qualified name of the artifact. For example, if you have this service:
package org.exampleclass MyService {
…
}then the name of the logger will be 'grails.app.services.org.example.MyService'.
For other classes, the typical approach is to store a logger based on the class name in a constant static field:
package org.otherimport org.apache.commons.logging.LogFactoryclass MyClass {
private static final log = LogFactory.getLog(this)
…
}This will create a logger with the name 'org.other.MyClass' - note the lack of a 'grails.app.' prefix since the class isn't an artifact. You can also pass a name to the
getLog() method, such as "myLogger", but this is less common because the logging system treats names with dots ('.') in a special way.
Configuring loggers
You have already seen how to configure loggers in Grails:
log4j = {
error 'org.codehaus.groovy.grails.web.servlet'
}This example configures loggers with names starting with 'org.codehaus.groovy.grails.web.servlet' to ignore any messages sent to them at a level of 'warn' or lower. But is there a logger with this name in the application? No. So why have a configuration for it? Because the above rule applies to any logger whose name
begins with 'org.codehaus.groovy.grails.web.servlet.' as well. For example, the rule applies to both the
org.codehaus.groovy.grails.web.servlet.GrailsDispatcherServlet class and the
org.codehaus.groovy.grails.web.servlet.mvc.GrailsWebRequest one.
In other words, loggers are hierarchical. This makes configuring them by package much simpler than it would otherwise be.
The most common things that you will want to capture log output from are your controllers, services, and other artifacts. Use the convention mentioned earlier to do that:
grails.app.<artifactType>.<className> . In particular the class name must be fully qualified, i.e. with the package if there is one:
log4j = {
// Set level for all application artifacts
info "grails.app" // Set for a specific controller in the default package
debug "grails.app.controllers.YourController" // Set for a specific domain class
debug "grails.app.domain.org.example.Book" // Set for all taglibs
info "grails.app.taglib"
}The standard artifact names used in the logging configuration are:
conf - For anything under grails-app/conf such as BootStrap.groovy (but excluding filters)filters - For filterstaglib - For tag librariesservices - For service classescontrollers - For controllersdomain - For domain entities
Grails itself generates plenty of logging information and it can sometimes be helpful to see that. Here are some useful loggers from Grails internals that you can use, especially when tracking down problems with your application:
org.codehaus.groovy.grails.commons - Core artifact information such as class loading etc.org.codehaus.groovy.grails.web - Grails web request processingorg.codehaus.groovy.grails.web.mapping - URL mapping debuggingorg.codehaus.groovy.grails.plugins - Log plugin activitygrails.spring - See what Spring beans Grails and plugins are definingorg.springframework - See what Spring is doingorg.hibernate - See what Hibernate is doing
So far, we've only looked at explicit configuration of loggers. But what about all those loggers that
don't have an explicit configuration? Are they simply ignored? The answer lies with the root logger.
The Root Logger
All logger objects inherit their configuration from the root logger, so if no explicit configuration is provided for a given logger, then any messages that go to that logger are subject to the rules defined for the root logger. In other words, the root logger provides the default configuration for the logging system.
Grails automatically configures the root logger to only handle messages at 'error' level and above, and all the messages are directed to the console (stdout for those with a C background). You can customise this behaviour by specifying a 'root' section in your logging configuration like so:
log4j = {
root {
info()
}
…
}The above example configures the root logger to log messages at 'info' level and above to the default console appender. You can also configure the root logger to log to one or more named appenders (which we'll talk more about shortly):
log4j = {
appenders {
file name:'file', file:'/var/logs/mylog.log'
}
root {
debug 'stdout', 'file'
}
}In the above example, the root logger will log to two appenders - the default 'stdout' (console) appender and a custom 'file' appender.
For power users there is an alternative syntax for configuring the root logger: the root
org.apache.log4j.Logger instance is passed as an argument to the log4j closure. This lets you work with the logger directly:
log4j = { root ->
root.level = org.apache.log4j.Level.DEBUG
…
}For more information on what you can do with this
Logger instance, refer to the Log4j API documentation.
Those are the basics of logging pretty well covered and they are sufficient if you're happy to only send log messages to the console. But what if you want to send them to a file? How do you make sure that messages from a particular logger go to a file but not the console? These questions and more will be answered as we look into appenders.
Appenders
Loggers are a useful mechanism for filtering messages, but they don't physically write the messages anywhere. That's the job of the appender, of which there are various types. For example, there is the default one that writes messages to the console, another that writes them to a file, and several others. You can even create your own appender implementations!
This diagram shows how they fit into the logging pipeline:
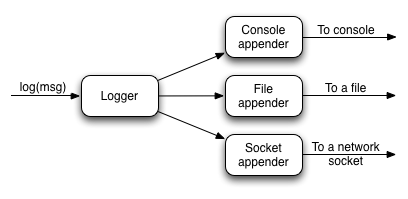
As you can see, a single logger may have several appenders attached to it. In a standard Grails configuration, the console appender named 'stdout' is attached to all loggers through the default root logger configuration. But that's the only one. Adding more appenders can be done within an 'appenders' block:
log4j = {
appenders {
rollingFile name: "myAppender",
maxFileSize: 1024,
file: "/tmp/logs/myApp.log"
}
}The following appenders are available by default:
Each named argument passed to an appender maps to a property of the underlying
Appender implementation. So the previous example sets the
name,
maxFileSize and
file properties of the
RollingFileAppender instance.
You can have as many appenders as you like - just make sure that they all have unique names. You can even have multiple instances of the same appender type, for example several file appenders that log to different files.
If you prefer to create the appender programmatically or if you want to use an appender implementation that's not available in the above syntax, simply declare an
appender entry with an instance of the appender you want:
import org.apache.log4j.*log4j = {
appenders {
appender new RollingFileAppender(
name: "myAppender",
maxFileSize: 1024,
file: "/tmp/logs/myApp.log")
}
}This approach can be used to configure
JMSAppender,
SocketAppender,
SMTPAppender, and more.
Once you have declared your extra appenders, you can attach them to specific loggers by passing the name as a key to one of the log level methods from the previous section:
error myAppender: "grails.app.controllers.BookController"
This will ensure that the 'grails.app.controllers.BookController' logger sends log messages to 'myAppender' as well as any appenders configured for the root logger. To add more than one appender to the logger, then add them to the same level declaration:
error myAppender: "grails.app.controllers.BookController",
myFileAppender: ["grails.app.controllers.BookController",
"grails.app.services.BookService"],
rollingFile: "grails.app.controllers.BookController"The above example also shows how you can configure more than one logger at a time for a given appender (
myFileAppender) by using a list.
Be aware that you can only configure a single level for a logger, so if you tried this code:
error myAppender: "grails.app.controllers.BookController"
debug myFileAppender: "grails.app.controllers.BookController"
fatal rollingFile: "grails.app.controllers.BookController"
you'd find that only 'fatal' level messages get logged for 'grails.app.controllers.BookController'. That's because the last level declared for a given logger wins. What you probably want to do is limit what level of messages an appender writes.
An appender that is attached to a logger configured with the 'all' level will generate a lot of logging information. That may be fine in a file, but it makes working at the console difficult. So we configure the console appender to only write out messages at 'info' level or above:
log4j = {
appenders {
console name: "stdout", threshold: org.apache.log4j.Level.INFO
}
}The key here is the
threshold argument which determines the cut-off for log messages. This argument is available for all appenders, but do note that you currently have to specify a
Level instance - a string such as "info" will not work.
Custom Layouts
By default the Log4j DSL assumes that you want to use a
PatternLayout. However, there are other layouts available including:
xml - Create an XML log filehtml - Creates an HTML log filesimple - A simple textual logpattern - A Pattern layout
You can specify custom patterns to an appender using the
layout setting:
log4j = {
appenders {
console name: "customAppender",
layout: pattern(conversionPattern: "%c{2} %m%n")
}
}This also works for the built-in appender "stdout", which logs to the console:
log4j = {
appenders {
console name: "stdout",
layout: pattern(conversionPattern: "%c{2} %m%n")
}
}Environment-specific configuration
Since the logging configuration is inside
Config.groovy, you can put it inside an environment-specific block. However, there is a problem with this approach: you have to provide the full logging configuration each time you define the
log4j setting. In other words, you cannot selectively override parts of the configuration - it's all or nothing.
To get around this, the logging DSL provides its own environment blocks that you can put anywhere in the configuration:
log4j = {
appenders {
console name: "stdout",
layout: pattern(conversionPattern: "%c{2} %m%n") environments {
production {
rollingFile name: "myAppender", maxFileSize: 1024,
file: "/tmp/logs/myApp.log"
}
}
} root {
//…
} // other shared config
info "grails.app.controller" environments {
production {
// Override previous setting for 'grails.app.controller'
error "grails.app.controllers"
}
}
}The one place you can't put an environment block is
inside the
root definition, but you can put the
root definition inside an environment block.
Full stacktraces
When exceptions occur, there can be an awful lot of noise in the stacktrace from Java and Groovy internals. Grails filters these typically irrelevant details and restricts traces to non-core Grails/Groovy class packages.
When this happens, the full trace is always logged to the
StackTrace logger, which by default writes its output to a file called
stacktrace.log. As with other loggers though, you can change its behaviour in the configuration. For example if you prefer full stack traces to go to the console, add this entry:
error stdout: "StackTrace"
This won't stop Grails from attempting to create the stacktrace.log file - it just redirects where stack traces are written to. An alternative approach is to change the location of the 'stacktrace' appender's file:
log4j = {
appenders {
rollingFile name: "stacktrace", maxFileSize: 1024,
file: "/var/tmp/logs/myApp-stacktrace.log"
}
}or, if you don't want to the 'stacktrace' appender at all, configure it as a 'null' appender:
log4j = {
appenders {
'null' name: "stacktrace"
}
}You can of course combine this with attaching the 'stdout' appender to the 'StackTrace' logger if you want all the output in the console.
Finally, you can completely disable stacktrace filtering by setting the
grails.full.stacktrace VM property to
true:
grails -Dgrails.full.stacktrace=true run-app
Masking Request Parameters From Stacktrace Logs
When Grails logs a stacktrace, the log message may include the names and values of all of the request parameters for the current request. To mask out the values of secure request parameters, specify the parameter names in the
grails.exceptionresolver.params.exclude config property:
grails.exceptionresolver.params.exclude = ['password', 'creditCard']
Request parameter logging may be turned off altogether by setting the
grails.exceptionresolver.logRequestParameters config property to
false. The default value is
true when the application is running in DEVELOPMENT mode and
false for all other modes.
grails.exceptionresolver.logRequestParameters=false
Logger inheritance
Earlier, we mentioned that all loggers inherit from the root logger and that loggers are hierarchical based on '.'-separated terms. What this means is that unless you override a parent setting, a logger retains the level and the appenders configured for that parent. So with this configuration:
log4j = {
appenders {
file name:'file', file:'/var/logs/mylog.log'
}
root {
debug 'stdout', 'file'
}
}all loggers in the application will have a level of 'debug' and will log to both the 'stdout' and 'file' appenders. What if you only want to log to 'stdout' for a particular logger? Change the 'additivity' for a logger in that case.
Additivity simply determines whether a logger inherits the configuration from its parent. If additivity is false, then its not inherited. The default for all loggers is true, i.e. they inherit the configuration. So how do you change this setting? Here's an example:
log4j = {
appenders {
…
}
root {
…
} info additivity: false,
stdout: ["grails.app.controllers.BookController",
"grails.app.services.BookService"]
}So when you specify a log level, add an 'additivity' named argument. Note that you when you specify the additivity, you must configure the loggers for a named appender. The following syntax will
not work:
info additivity: false, ["grails.app.controllers.BookController",
"grails.app.services.BookService"]Customizing stack trace printing and filtering
Stacktraces in general and those generated when using Groovy in particular are quite verbose and contain many stack frames that aren't interesting when diagnosing problems. So Grails uses a implementation of the
org.codehaus.groovy.grails.exceptions.StackTraceFilterer interface to filter out irrelevant stack frames. To customize the approach used for filtering, implement that interface in a class in src/groovy or src/java and register it in
Config.groovy:
grails.logging.stackTraceFiltererClass =
'com.yourcompany.yourapp.MyStackTraceFilterer'In addition, Grails customizes the display of the filtered stacktrace to make the information more readable. To customize this, implement the
org.codehaus.groovy.grails.exceptions.StackTracePrinter interface in a class in src/groovy or src/java and register it in
Config.groovy:
grails.logging.stackTracePrinterClass =
'com.yourcompany.yourapp.MyStackTracePrinter'Finally, to render error information in the error GSP, an HTML-generating printer implementation is needed. The default implementation is
org.codehaus.groovy.grails.web.errors.ErrorsViewStackTracePrinter and it's registered as a Spring bean. To use your own implementation, either implement the
org.codehaus.groovy.grails.exceptions.StackTraceFilterer directly or subclass
ErrorsViewStackTracePrinter and register it in
grails-app/conf/spring/resources.groovy as:
import com.yourcompany.yourapp.MyErrorsViewStackTracePrinterbeans = { errorsViewStackTracePrinter(MyErrorsViewStackTracePrinter,
ref('grailsResourceLocator'))
}Alternative logging libraries
By default, Grails uses Log4J to do its logging. For most people this is absolutely fine, and many users don't even care what logging library is used. But if you're not one of those and want to use an alternative, such as the
JDK logging package or
logback, you can do so by simply excluding a couple of dependencies from the global set and adding your own:
grails.project.dependency.resolution = {
inherits("global") {
excludes "grails-plugin-logging", "log4j"
}
…
dependencies {
runtime "ch.qos.logback:logback-core:0.9.29"
…
}
…
}If you do this, you will get unfiltered, standard Java stacktraces in your log files and you won't be able to use the logging configuration DSL that's just been described. Instead, you will have to use the standard configuration mechanism for the library you choose.
5.1.3 GORM
Grails provides the following GORM configuration options:
grails.gorm.failOnError - If set to true, causes the save() method on domain classes to throw a grails.validation.ValidationException if validation fails during a save. This option may also be assigned a list of Strings representing package names. If the value is a list of Strings then the failOnError behavior will only be applied to domain classes in those packages (including sub-packages). See the save method docs for more information.
For example, to enable failOnError for all domain classes:
grails.gorm.failOnError=true
and to enable failOnError for domain classes by package:
grails.gorm.failOnError = ['com.companyname.somepackage',
'com.companyname.someotherpackage']
grails.gorm.autoFlush = If set to true, causes the merge, save and delete methods to flush the session, replacing the need to explicitly flush using save(flush: true).
5.2 Environments
Per Environment Configuration
Grails supports the concept of per environment configuration. The
Config.groovy,
DataSource.groovy, and
BootStrap.groovy files in the
grails-app/conf directory can use per-environment configuration using the syntax provided by
ConfigSlurper. As an example consider the following default
DataSource definition provided by Grails:
dataSource {
pooled = false
driverClassName = "org.h2.Driver"
username = "sa"
password = ""
}
environments {
development {
dataSource {
dbCreate = "create-drop"
url = "jdbc:h2:mem:devDb"
}
}
test {
dataSource {
dbCreate = "update"
url = "jdbc:h2:mem:testDb"
}
}
production {
dataSource {
dbCreate = "update"
url = "jdbc:h2:prodDb"
}
}
}Notice how the common configuration is provided at the top level and then an
environments block specifies per environment settings for the
dbCreate and
url properties of the
DataSource.
Packaging and Running for Different Environments
Grails'
command line has built in capabilities to execute any command within the context of a specific environment. The format is:
grails [environment] [command name]
In addition, there are 3 preset environments known to Grails:
dev,
prod, and
test for
development,
production and
test. For example to create a WAR for the
test environment you wound run:
To target other environments you can pass a
grails.env variable to any command:
grails -Dgrails.env=UAT run-app
Programmatic Environment Detection
Within your code, such as in a Gant script or a bootstrap class you can detect the environment using the
Environment class:
import grails.util.Environment...switch (Environment.current) {
case Environment.DEVELOPMENT:
configureForDevelopment()
break
case Environment.PRODUCTION:
configureForProduction()
break
}Per Environment Bootstrapping
It's often desirable to run code when your application starts up on a per-environment basis. To do so you can use the
grails-app/conf/BootStrap.groovy file's support for per-environment execution:
def init = { ServletContext ctx ->
environments {
production {
ctx.setAttribute("env", "prod")
}
development {
ctx.setAttribute("env", "dev")
}
}
ctx.setAttribute("foo", "bar")
}Generic Per Environment Execution
The previous
BootStrap example uses the
grails.util.Environment class internally to execute. You can also use this class yourself to execute your own environment specific logic:
Environment.executeForCurrentEnvironment {
production {
// do something in production
}
development {
// do something only in development
}
}5.3 The DataSource
Since Grails is built on Java technology setting up a data source requires some knowledge of JDBC (the technology that doesn't stand for Java Database Connectivity).
If you use a database other than H2 you need a JDBC driver. For example for MySQL you would need
Connector/JDrivers typically come in the form of a JAR archive. It's best to use the dependency resolution to resolve the jar if it's available in a Maven repository, for example you could add a dependency for the MySQL driver like this:
dependencies {
runtime 'mysql:mysql-connector-java:5.1.29'
}If you can't use dependency resolution then just put the JAR in your project's
lib directory.
Once you have the JAR resolved you need to get familiar Grails' DataSource descriptor file located at
grails-app/conf/DataSource.groovy. This file contains the dataSource definition which includes the following settings:
driverClassName - The class name of the JDBC driverusername - The username used to establish a JDBC connectionpassword - The password used to establish a JDBC connectionurl - The JDBC URL of the databasedbCreate - Whether to auto-generate the database from the domain model - one of 'create-drop', 'create', 'update' or 'validate'pooled - Whether to use a pool of connections (defaults to true)logSql - Enable SQL logging to stdoutformatSql - Format logged SQLdialect - A String or Class that represents the Hibernate dialect used to communicate with the database. See the org.hibernate.dialect package for available dialects.readOnly - If true makes the DataSource read-only, which results in the connection pool calling setReadOnly(true) on each Connectiontransactional - If false leaves the DataSource's transactionManager bean outside the chained BE1PC transaction manager implementation. This only applies to additional datasources.persistenceInterceptor - The default datasource is automatically wired up to the persistence interceptor, other datasources are not wired up automatically unless this is set to trueproperties - Extra properties to set on the DataSource bean. See the Tomcat Pool documentation. There is also a Javadoc format documentation of the properties.jmxExport - If false, will disable registration of JMX MBeans for all DataSources. By default JMX MBeans are added for DataSources with jmxEnabled = true in properties.
A typical configuration for MySQL may be something like:
dataSource {
pooled = true
dbCreate = "update"
url = "jdbc:mysql://localhost:3306/my_database"
driverClassName = "com.mysql.jdbc.Driver"
dialect = org.hibernate.dialect.MySQL5InnoDBDialect
username = "username"
password = "password"
properties {
jmxEnabled = true
initialSize = 5
maxActive = 50
minIdle = 5
maxIdle = 25
maxWait = 10000
maxAge = 10 * 60000
timeBetweenEvictionRunsMillis = 5000
minEvictableIdleTimeMillis = 60000
validationQuery = "SELECT 1"
validationQueryTimeout = 3
validationInterval = 15000
testOnBorrow = true
testWhileIdle = true
testOnReturn = false
jdbcInterceptors = "ConnectionState;StatementCache(max=200)"
defaultTransactionIsolation = java.sql.Connection.TRANSACTION_READ_COMMITTED
}
}
When configuring the DataSource do not include the type or the def keyword before any of the configuration settings as Groovy will treat these as local variable definitions and they will not be processed. For example the following is invalid:
dataSource {
boolean pooled = true // type declaration results in ignored local variable
…
}Example of advanced configuration using extra properties:
dataSource {
pooled = true
dbCreate = "update"
url = "jdbc:mysql://localhost:3306/my_database"
driverClassName = "com.mysql.jdbc.Driver"
dialect = org.hibernate.dialect.MySQL5InnoDBDialect
username = "username"
password = "password"
properties {
// Documentation for Tomcat JDBC Pool
// http://tomcat.apache.org/tomcat-7.0-doc/jdbc-pool.html#Common_Attributes
// https://tomcat.apache.org/tomcat-7.0-doc/api/org/apache/tomcat/jdbc/pool/PoolConfiguration.html
jmxEnabled = true
initialSize = 5
maxActive = 50
minIdle = 5
maxIdle = 25
maxWait = 10000
maxAge = 10 * 60000
timeBetweenEvictionRunsMillis = 5000
minEvictableIdleTimeMillis = 60000
validationQuery = "SELECT 1"
validationQueryTimeout = 3
validationInterval = 15000
testOnBorrow = true
testWhileIdle = true
testOnReturn = false
ignoreExceptionOnPreLoad = true
// http://tomcat.apache.org/tomcat-7.0-doc/jdbc-pool.html#JDBC_interceptors
jdbcInterceptors = "ConnectionState;StatementCache(max=200)"
defaultTransactionIsolation = java.sql.Connection.TRANSACTION_READ_COMMITTED // safe default
// controls for leaked connections
abandonWhenPercentageFull = 100 // settings are active only when pool is full
removeAbandonedTimeout = 120
removeAbandoned = true
// use JMX console to change this setting at runtime
logAbandoned = false // causes stacktrace recording overhead, use only for debugging
// JDBC driver properties
// Mysql as example
dbProperties {
// Mysql specific driver properties
// http://dev.mysql.com/doc/connector-j/en/connector-j-reference-configuration-properties.html
// let Tomcat JDBC Pool handle reconnecting
autoReconnect=false
// truncation behaviour
jdbcCompliantTruncation=false
// mysql 0-date conversion
zeroDateTimeBehavior='convertToNull'
// Tomcat JDBC Pool's StatementCache is used instead, so disable mysql driver's cache
cachePrepStmts=false
cacheCallableStmts=false
// Tomcat JDBC Pool's StatementFinalizer keeps track
dontTrackOpenResources=true
// performance optimization: reduce number of SQLExceptions thrown in mysql driver code
holdResultsOpenOverStatementClose=true
// enable MySQL query cache - using server prep stmts will disable query caching
useServerPrepStmts=false
// metadata caching
cacheServerConfiguration=true
cacheResultSetMetadata=true
metadataCacheSize=100
// timeouts for TCP/IP
connectTimeout=15000
socketTimeout=120000
// timer tuning (disable)
maintainTimeStats=false
enableQueryTimeouts=false
// misc tuning
noDatetimeStringSync=true
}
}
}More on dbCreate
Hibernate can automatically create the database tables required for your domain model. You have some control over when and how it does this through the
dbCreate property, which can take these values:
- create - Drops the existing schema and creates the schema on startup, dropping existing tables, indexes, etc. first.
- create-drop - Same as create, but also drops the tables when the application shuts down cleanly.
- update - Creates missing tables and indexes, and updates the current schema without dropping any tables or data. Note that this can't properly handle many schema changes like column renames (you're left with the old column containing the existing data).
- validate - Makes no changes to your database. Compares the configuration with the existing database schema and reports warnings.
- any other value - does nothing
You can also remove the
dbCreate setting completely, which is recommended once your schema is relatively stable and definitely when your application and database are deployed in production. Database changes are then managed through proper migrations, either with SQL scripts or a migration tool like
Liquibase (the
Database Migration plugin uses Liquibase and is tightly integrated with Grails and GORM).
5.3.1 DataSources and Environments
The previous example configuration assumes you want the same config for all environments: production, test, development etc.
Grails' DataSource definition is "environment aware", however, so you can do:
dataSource {
pooled = true
driverClassName = "com.mysql.jdbc.Driver"
dialect = org.hibernate.dialect.MySQL5InnoDBDialect
// other common settings here
}environments {
production {
dataSource {
url = "jdbc:mysql://liveip.com/liveDb"
// other environment-specific settings here
}
}
}5.3.2 JNDI DataSources
Referring to a JNDI DataSource
Most Java EE containers supply
DataSource instances via
Java Naming and Directory Interface (JNDI). Grails supports the definition of JNDI data sources as follows:
dataSource {
jndiName = "java:comp/env/myDataSource"
}The format on the JNDI name may vary from container to container, but the way you define the
DataSource in Grails remains the same.
Configuring a Development time JNDI resource
The way in which you configure JNDI data sources at development time is plugin dependent. Using the
Tomcat plugin you can define JNDI resources using the
grails.naming.entries setting in
grails-app/conf/Config.groovy:
grails.naming.entries = [
"bean/MyBeanFactory": [
auth: "Container",
type: "com.mycompany.MyBean",
factory: "org.apache.naming.factory.BeanFactory",
bar: "23"
],
"jdbc/EmployeeDB": [
type: "javax.sql.DataSource", //required
auth: "Container", // optional
description: "Data source for Foo", //optional
driverClassName: "org.h2.Driver",
url: "jdbc:h2:mem:database",
username: "dbusername",
password: "dbpassword",
maxActive: "8",
maxIdle: "4"
],
"mail/session": [
type: "javax.mail.Session,
auth: "Container",
"mail.smtp.host": "localhost"
]
]5.3.3 Automatic Database Migration
The
dbCreate property of the
DataSource definition is important as it dictates what Grails should do at runtime with regards to automatically generating the database tables from
GORM classes. The options are described in the
DataSource section:
createcreate-dropupdatevalidate- no value
In
development mode
dbCreate is by default set to "create-drop", but at some point in development (and certainly once you go to production) you'll need to stop dropping and re-creating the database every time you start up your server.
It's tempting to switch to
update so you retain existing data and only update the schema when your code changes, but Hibernate's update support is very conservative. It won't make any changes that could result in data loss, and doesn't detect renamed columns or tables, so you'll be left with the old one and will also have the new one.
Grails supports migrations via the
Database Migration plugin which can be installed by declaring the plugin in
grails-app/conf/BuildConfig.groovy:
grails.project.dependency.resolution = {
…
plugins {
runtime ':database-migration:1.3.1'
}
}The plugin uses
Liquibase and provides access to all of its functionality, and also has support for GORM (for example generating a change set by comparing your domain classes to a database).
5.3.4 Transaction-aware DataSource Proxy
The actual
dataSource bean is wrapped in a transaction-aware proxy so you will be given the connection that's being used by the current transaction or Hibernate
Session if one is active.
If this were not the case, then retrieving a connection from the
dataSource would be a new connection, and you wouldn't be able to see changes that haven't been committed yet (assuming you have a sensible transaction isolation setting, e.g.
READ_COMMITTED or better).
The "real" unproxied
dataSource is still available to you if you need access to it; its bean name is
dataSourceUnproxied.
You can access this bean like any other Spring bean, i.e. using dependency injection:
class MyService { def dataSourceUnproxied
…
}or by pulling it from the
ApplicationContext:
def dataSourceUnproxied = ctx.dataSourceUnproxied
5.3.5 Database Console
The
H2 database console is a convenient feature of H2 that provides a web-based interface to any database that you have a JDBC driver for, and it's very useful to view the database you're developing against. It's especially useful when running against an in-memory database.
You can access the console by navigating to
http://localhost:8080/appname/dbconsole in a browser. The URI can be configured using the
grails.dbconsole.urlRoot attribute in Config.groovy and defaults to
'/dbconsole'.
The console is enabled by default in development mode and can be disabled or enabled in other environments by using the
grails.dbconsole.enabled attribute in Config.groovy. For example you could enable the console in production using
environments {
production {
grails.serverURL = "http://www.changeme.com"
grails.dbconsole.enabled = true
grails.dbconsole.urlRoot = '/admin/dbconsole'
}
development {
grails.serverURL = "http://localhost:8080/${appName}"
}
test {
grails.serverURL = "http://localhost:8080/${appName}"
}
}
If you enable the console in production be sure to guard access to it using a trusted security framework.
Configuration
By default the console is configured for an H2 database which will work with the default settings if you haven't configured an external database - you just need to change the JDBC URL to
jdbc:h2:mem:devDB. If you've configured an external database (e.g. MySQL, Oracle, etc.) then you can use the Saved Settings dropdown to choose a settings template and fill in the url and username/password information from your DataSource.groovy.
5.3.6 Multiple Datasources
By default all domain classes share a single
DataSource and a single database, but you have the option to partition your domain classes into two or more
DataSources.
Configuring Additional DataSources
The default
DataSource configuration in
grails-app/conf/DataSource.groovy looks something like this:
dataSource {
pooled = true
driverClassName = "org.h2.Driver"
username = "sa"
password = ""
}
hibernate {
cache.use_second_level_cache = true
cache.use_query_cache = true
cache.provider_class = 'net.sf.ehcache.hibernate.EhCacheProvider'
}environments {
development {
dataSource {
dbCreate = "create-drop"
url = "jdbc:h2:mem:devDb"
}
}
test {
dataSource {
dbCreate = "update"
url = "jdbc:h2:mem:testDb"
}
}
production {
dataSource {
dbCreate = "update"
url = "jdbc:h2:prodDb"
}
}
}This configures a single
DataSource with the Spring bean named
dataSource. To configure extra
DataSources, add another
dataSource block (at the top level, in an environment block, or both, just like the standard
DataSource definition) with a custom name, separated by an underscore. For example, this configuration adds a second
DataSource, using MySQL in the development environment and Oracle in production:
environments {
development {
dataSource {
dbCreate = "create-drop"
url = "jdbc:h2:mem:devDb"
}
dataSource_lookup {
dialect = org.hibernate.dialect.MySQLInnoDBDialect
driverClassName = 'com.mysql.jdbc.Driver'
username = 'lookup'
password = 'secret'
url = 'jdbc:mysql://localhost/lookup'
dbCreate = 'update'
}
}
test {
dataSource {
dbCreate = "update"
url = "jdbc:h2:mem:testDb"
}
}
production {
dataSource {
dbCreate = "update"
url = "jdbc:h2:prodDb"
}
dataSource_lookup {
dialect = org.hibernate.dialect.Oracle10gDialect
driverClassName = 'oracle.jdbc.driver.OracleDriver'
username = 'lookup'
password = 'secret'
url = 'jdbc:oracle:thin:@localhost:1521:lookup'
dbCreate = 'update'
}
}
}You can use the same or different databases as long as they're supported by Hibernate.
Configuring Domain Classes
If a domain class has no
DataSource configuration, it defaults to the standard
'dataSource'. Set the
datasource property in the
mapping block to configure a non-default
DataSource. For example, if you want to use the
ZipCode domain to use the
'lookup' DataSource, configure it like this;
class ZipCode { String code static mapping = {
datasource 'lookup'
}
}A domain class can also use two or more
DataSources. Use the
datasources property with a list of names to configure more than one, for example:
class ZipCode { String code static mapping = {
datasources(['lookup', 'auditing'])
}
}If a domain class uses the default
DataSource and one or more others, use the special name
'DEFAULT' to indicate the default
DataSource:
class ZipCode { String code static mapping = {
datasources(['lookup', 'DEFAULT'])
}
}If a domain class uses all configured
DataSources use the special value
'ALL':
class ZipCode { String code static mapping = {
datasource 'ALL'
}
}Namespaces and GORM Methods
If a domain class uses more than one
DataSource then you can use the namespace implied by each
DataSource name to make GORM calls for a particular
DataSource. For example, consider this class which uses two
DataSources:
class ZipCode { String code static mapping = {
datasources(['lookup', 'auditing'])
}
}The first
DataSource specified is the default when not using an explicit namespace, so in this case we default to 'lookup'. But you can call GORM methods on the 'auditing'
DataSource with the
DataSource name, for example:
def zipCode = ZipCode.auditing.get(42)
…
zipCode.auditing.save()
As you can see, you add the
DataSource to the method call in both the static case and the instance case.
Hibernate Mapped Domain Classes
You can also partition annotated Java classes into separate datasources. Classes using the default datasource are registered in
grails-app/conf/hibernate/hibernate.cfg.xml. To specify that an annotated class uses a non-default datasource, create a
hibernate.cfg.xml file for that datasource with the file name prefixed with the datasource name.
For example if the
Book class is in the default datasource, you would register that in
grails-app/conf/hibernate/hibernate.cfg.xml:
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
'-//Hibernate/Hibernate Configuration DTD 3.0//EN'
'http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd'>
<hibernate-configuration>
<session-factory>
<mapping class='org.example.Book'/>
</session-factory>
</hibernate-configuration>and if the
Library class is in the "ds2" datasource, you would register that in
grails-app/conf/hibernate/ds2_hibernate.cfg.xml:
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
'-//Hibernate/Hibernate Configuration DTD 3.0//EN'
'http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd'>
<hibernate-configuration>
<session-factory>
<mapping class='org.example.Library'/>
</session-factory>
</hibernate-configuration>The process is the same for classes mapped with hbm.xml files - just list them in the appropriate hibernate.cfg.xml file.
Services
Like Domain classes, by default Services use the default
DataSource and
PlatformTransactionManager. To configure a Service to use a different
DataSource, use the static
datasource property, for example:
class DataService { static datasource = 'lookup' void someMethod(...) {
…
}
}A transactional service can only use a single
DataSource, so be sure to only make changes for domain classes whose
DataSource is the same as the Service.
Note that the datasource specified in a service has no bearing on which datasources are used for domain classes; that's determined by their declared datasources in the domain classes themselves. It's used to declare which transaction manager to use.
What you'll see is that if you have a Foo domain class in dataSource1 and a Bar domain class in dataSource2, and WahooService uses dataSource1, a service method that saves a new Foo and a new Bar will only be transactional for Foo since they share the datasource. The transaction won't affect the Bar instance. If you want both to be transactional you'd need to use two services and XA datasources for two-phase commit, e.g. with the Atomikos plugin.
Transactions across multiple datasources
Grails uses the Best Efforts 1PC pattern for handling transactions across multiple datasources.
The
Best Efforts 1PC pattern is fairly general but can fail in some circumstances that the developer must be aware of. This is a non-XA pattern that involves a synchronized single-phase commit of a number of resources. Because the
2PC is not used, it can never be as safe as an
XA transaction, but is often good enough if the participants are aware of the compromises.
The basic idea is to delay the commit of all resources as late as possible in a transaction so that the only thing that can go wrong is an infrastructure failure (not a business-processing error). Systems that rely on Best Efforts 1PC reason that infrastructure failures are rare enough that they can afford to take the risk in return for higher throughput. If business-processing services are also designed to be idempotent, then little can go wrong in practice.
The BE1PC implementation was added in Grails 2.3.6. . Before this change additional datasources didn't take part in transactions initiated in Grails. The transactions in additional datasources were basically in auto commit mode. In some cases this might be the wanted behavior. One reason might be performance: on the start of each new transaction, the BE1PC transaction manager creates a new transaction to each datasource. It's possible to leave an additional datasource out of the BE1PC transaction manager by setting
transactional = false in the respective configuration block of the additional dataSource. Datasources with
readOnly = true will also be left out of the chained transaction manager (since 2.3.7).
By default, the BE1PC implementation will add all beans implementing the Spring
PlatformTransactionManager interface to the chained BE1PC transaction manager. For example, a possible
JMSTransactionManager bean in the Grails application context would be added to the Grails BE1PC transaction manager's chain of transaction managers.
You can exclude transaction manager beans from the BE1PC implementation with the this configuration option:
grails.transaction.chainedTransactionManagerPostProcessor.blacklistPattern = '.*'
The exclude matching is done on the name of the transaction manager bean. The transaction managers of datasources with
transactional = false or
readOnly = true will be skipped and using this configuration option is not required in that case.
XA and Two-phase Commit
When the Best Efforts 1PC pattern isn't suitable for handling transactions across multiple transactional resources (not only datasources), there are several options available for adding XA/2PC support to Grails applications.
The
Spring transactions documentation contains information about integrating the JTA/XA transaction manager of different application servers. In this case, you can configure a bean with the name
transactionManager manually in
resources.groovy or
resources.xml file.
There is also
Atomikos plugin available for XA support in Grails applications.
5.4 Externalized Configuration
Some deployments require that configuration be sourced from more than one place and be changeable without requiring a rebuild of the application. In order to support deployment scenarios such as these the configuration can be externalized. To do so, point Grails at the locations of the configuration files that should be used by adding a
grails.config.locations setting in
Config.groovy, for example:
grails.config.locations = [
"classpath:${appName}-config.properties",
"classpath:${appName}-config.groovy",
"file:${userHome}/.grails/${appName}-config.properties",
"file:${userHome}/.grails/${appName}-config.groovy" ]In the above example we're loading configuration files (both Java Properties files and
ConfigSlurper configurations) from different places on the classpath and files located in
USER_HOME.
It is also possible to load config by specifying a class that is a config script.
grails.config.locations = [com.my.app.MyConfig]
This can be useful in situations where the config is either coming from a plugin or some other part of your application. A typical use for this is re-using configuration provided by plugins across multiple applications.
Ultimately all configuration files get merged into the
config property of the
GrailsApplication object and are hence obtainable from there.
Values that have the same name as previously defined values will overwrite the existing values, and the pointed to configuration sources are loaded in the order in which they are defined.
Config Defaults
The configuration values contained in the locations described by the
grails.config.locations property will
override any values defined in your application
Config.groovy file which may not be what you want. You may want to have a set of
default values be be loaded that can be overridden in either your application's
Config.groovy file or in a named config location. For this you can use the
grails.config.defaults.locations property.
This property supports the same values as the
grails.config.locations property (i.e. paths to config scripts, property files or classes), but the config described by
grails.config.defaults.locations will be loaded
before all other values and can therefore be overridden. Some plugins use this mechanism to supply one or more sets of default configuration that you can choose to include in your application config.
Grails also supports the concept of property place holders and property override configurers as defined in Spring For more information on these see the section on Grails and Spring
5.5 Versioning
Versioning Basics
Grails has built in support for application versioning. The version of the application is set to
0.1 when you first create an application with the
create-app command. The version is stored in the application meta data file
application.properties in the root of the project.
To change the version of your application you can edit the file manually, or run the
set-version command:
The version is used in various commands including the
war command which will append the application version to the end of the created WAR file.
Detecting Versions at Runtime
You can detect the application version using Grails' support for application metadata using the
GrailsApplication class. For example within
controllers there is an implicit
grailsApplication variable that can be used:
def version = grailsApplication.metadata['app.version']
You can retrieve the version of Grails that is running with:
def grailsVersion = grailsApplication.metadata['app.grails.version']
or the
GrailsUtil class:
import grails.util.GrailsUtil
…
def grailsVersion = GrailsUtil.grailsVersion
5.6 Project Documentation
Since Grails 1.2, the documentation engine that powers the creation of this documentation has been available for your own Grails projects.
The documentation engine uses a variation on the
Textile syntax to automatically create project documentation with smart linking, formatting etc.
Creating project documentation
To use the engine you need to follow a few conventions. First, you need to create a
src/docs/guide directory where your documentation source files will go. Then, you need to create the source docs themselves. Each chapter should have its own gdoc file as should all numbered sub-sections. You will end up with something like:
+ src/docs/guide/introduction.gdoc
+ src/docs/guide/introduction/changes.gdoc
+ src/docs/guide/gettingStarted.gdoc
+ src/docs/guide/configuration.gdoc
+ src/docs/guide/configuration/build.gdoc
+ src/docs/guide/configuration/build/controllers.gdoc
Note that you can have all your gdoc files in the top-level directory if you want, but you can also put sub-sections in sub-directories named after the parent section - as the above example shows.
Once you have your source files, you still need to tell the documentation engine what the structure of your user guide is going to be. To do that, you add a
src/docs/guide/toc.yml file that contains the structure and titles for each section. This file is in
YAML format and basically represents the structure of the user guide in tree form. For example, the above files could be represented as:
introduction:
title: Introduction
changes: Change Log
gettingStarted: Getting Started
configuration:
title: Configuration
build:
title: Build Config
controllers: Specifying ControllersThe format is pretty straightforward. Any section that has sub-sections is represented with the corresponding filename (minus the .gdoc extension) followed by a colon. The next line should contain
title: plus the title of the section as seen by the end user. Every sub-section then has its own line after the title. Leaf nodes, i.e. those without any sub-sections, declare their title on the same line as the section name but after the colon.
That's it. You can easily add, remove, and move sections within the
toc.yml to restructure the generated user guide. You should also make sure that all section names, i.e. the gdoc filenames, should be unique since they are used for creating internal links and for the HTML filenames. Don't worry though, the documentation engine will warn you of duplicate section names.
Creating reference items
Reference items appear in the Quick Reference section of the documentation. Each reference item belongs to a category and a category is a directory located in the
src/docs/ref directory. For example, suppose you have defined a new controller method called
renderPDF. That belongs to the
Controllers category so you would create a gdoc text file at the following location:
+ src/docs/ref/Controllers/renderPDF.gdoc
Configuring Output Properties
There are various properties you can set within your
grails-app/conf/Config.groovy file that customize the output of the documentation such as:
- grails.doc.title - The title of the documentation
- grails.doc.subtitle - The subtitle of the documentation
- grails.doc.authors - The authors of the documentation
- grails.doc.license - The license of the software
- grails.doc.copyright - The copyright message to display
- grails.doc.footer - The footer to use
Other properties such as the version are pulled from your project itself. If a title is not specified, the application name is used.
You can also customise the look of the documentation and provide images by setting a few other options:
- grails.doc.css - The location of a directory containing custom CSS files (type
java.io.File)
- grails.doc.js - The location of a directory containing custom JavaScript files (type
java.io.File)
- grails.doc.style - The location of a directory containing custom HTML templates for the guide (type
java.io.File)
- grails.doc.images - The location of a directory containing image files for use in the style templates and within the documentation pages themselves (type
java.io.File)
One of the simplest ways to customise the look of the generated guide is to provide a value for
grails.doc.css and then put a custom.css file in the corresponding directory. Grails will automatically include this CSS file in the guide. You can also place a custom-pdf.css file in that directory. This allows you to override the styles for the PDF version of the guide.
Generating Documentation
Once you have created some documentation (refer to the syntax guide in the next chapter) you can generate an HTML version of the documentation using the command:
This command will output an
docs/manual/index.html which can be opened in a browser to view your documentation.
Documentation Syntax
As mentioned the syntax is largely similar to Textile or Confluence style wiki markup. The following sections walk you through the syntax basics.
Basic Formatting
Monospace:
monospace
Italic:
italic
Bold:
bold
Image:

!http://grails.org/images/new/grailslogo_topNav.png!
You can also link to internal images like so:
!someFolder/my_diagram.png!
This will link to an image stored locally within your project. There is currently no default location for doc images, but you can specify one with the
grails.doc.images setting in Config.groovy like so:
grails.doc.images = new File("src/docs/images")In this example, you would put the my_diagram.png file in the directory 'src/docs/images/someFolder'.
Linking
There are several ways to create links with the documentation generator. A basic external link can either be defined using confluence or textile style markup:
[Pivotal|http://www.pivotal.io/oss]
or
"Pivotal":http://www.pivotal.io/oss
For links to other sections inside the user guide you can use the
guide: prefix with the name of the section you want to link to:
[Intro|guide:introduction]
The section name comes from the corresponding gdoc filename. The documentation engine will warn you if any links to sections in your guide break.
To link to reference items you can use a special syntax:
In this case the category of the reference item is on the right hand side of the | and the name of the reference item on the left.
Finally, to link to external APIs you can use the
api: prefix. For example:
[String|api:java.lang.String]
The documentation engine will automatically create the appropriate javadoc link in this case. To add additional APIs to the engine you can configure them in
grails-app/conf/Config.groovy. For example:
grails.doc.api.org.hibernate=
"http://docs.jboss.org/hibernate/stable/core/javadocs"The above example configures classes within the
org.hibernate package to link to the Hibernate website's API docs.
Lists and Headings
Headings can be created by specifying the letter 'h' followed by a number and then a dot:
h3.<space>Heading3
h4.<space>Heading4
Unordered lists are defined with the use of the * character:
* item 1
** subitem 1
** subitem 2
* item 2
Numbered lists can be defined with the # character:
Tables can be created using the
table macro:
| Name | Number |
|---|
| Albert | 46 |
| Wilma | 1348 |
| James | 12 |
{table}
*Name* | *Number*
Albert | 46
Wilma | 1348
James | 12
{table}Code and Notes
You can define code blocks with the
code macro:
class Book {
String title
}{code}
class Book {
String title
}
{code}The example above provides syntax highlighting for Java and Groovy code, but you can also highlight XML markup:
{code:xml}
<hello>world</hello>
{code}There are also a couple of macros for displaying notes and warnings:
Note:
This is a note!
{note}
This is a note!
{note}Warning:
This is a warning!
{warning}
This is a warning!
{warning}5.7 Dependency Resolution
Grails features a dependency resolution DSL that lets you control how plugins and JAR dependencies are resolved.
You can choose to use Aether (since Grails 2.3) or Apache Ivy as the dependency resolution engine. Aether is the dependency resolution library used by the Maven build tool, so if you are looking for Maven-like behavior then Aether is the better choice. Ivy allows more flexibility if you wish to resolve jars from flat file systems or none HTTP repositories. Aether is the default dependency resolution engine for Grails applications since Grails 2.3.
As of Grails 2.4 the Ivy resolver is considered deprecated and no longer maintained. It is recommended all users switch to using Aether.
To configure which dependency resolution engine to use you can specify the
grails.project.dependency.resolver setting in
grails-app/conf/BuildConfig.groovy. The default setting is shown below:
grails.project.dependency.resolver = "maven" // or ivy
You can then specify a
grails.project.dependency.resolution property inside the
grails-app/conf/BuildConfig.groovy file that configures how dependencies are resolved:
grails.project.dependency.resolution = {
// config here
}The default configuration looks like the following:
grails.servlet.version = "3.0" // Change depending on target container compliance (2.5 or 3.0)
grails.project.class.dir = "target/classes"
grails.project.test.class.dir = "target/test-classes"
grails.project.test.reports.dir = "target/test-reports"
grails.project.work.dir = "target/work"
grails.project.target.level = 1.6
grails.project.source.level = 1.6
//grails.project.war.file = "target/${appName}-${appVersion}.war"grails.project.fork = [
// configure settings for compilation JVM, note that if you alter the Groovy version forked compilation is required
// compile: [maxMemory: 256, minMemory: 64, debug: false, maxPerm: 256, daemon:true], // configure settings for the test-app JVM, uses the daemon by default
test: [maxMemory: 768, minMemory: 64, debug: false, maxPerm: 256, daemon:true],
// configure settings for the run-app JVM
run: [maxMemory: 768, minMemory: 64, debug: false, maxPerm: 256, forkReserve:false],
// configure settings for the run-war JVM
war: [maxMemory: 768, minMemory: 64, debug: false, maxPerm: 256, forkReserve:false],
// configure settings for the Console UI JVM
console: [maxMemory: 768, minMemory: 64, debug: false, maxPerm: 256]
]grails.project.dependency.resolver = "maven" // or ivy
grails.project.dependency.resolution = {
// inherit Grails' default dependencies
inherits("global") {
// specify dependency exclusions here; for example, uncomment this to disable ehcache:
// excludes 'ehcache'
}
log "error" // log level of Ivy resolver, either 'error', 'warn', 'info', 'debug' or 'verbose'
checksums true // Whether to verify checksums on resolve
legacyResolve false // whether to do a secondary resolve on plugin installation, not advised and here for backwards compatibility repositories {
inherits true // Whether to inherit repository definitions from plugins grailsPlugins()
grailsHome()
mavenLocal()
grailsCentral()
mavenCentral()
// uncomment these (or add new ones) to enable remote dependency resolution from public Maven repositories
//mavenRepo "http://repository.codehaus.org"
//mavenRepo "http://download.java.net/maven/2/"
} dependencies {
// specify dependencies here under either 'build', 'compile', 'runtime', 'test' or 'provided' scopes e.g.
runtime 'mysql:mysql-connector-java:5.1.24'
compile 'org.springframework.integration:spring-integration-core:2.2.5.RELEASE'
} plugins {
// plugins for the build system only
}
}The details of the above will be explained in the next few sections.
5.7.1 Configurations and Dependencies
Grails features five dependency resolution configurations (or 'scopes'):
-
build: Dependencies for the build system only
-
compile: Dependencies for the compile step
-
runtime: Dependencies needed at runtime but not for compilation (see above)
-
test: Dependencies needed for testing but not at runtime (see above)
-
provided: Dependencies needed at development time, but not during WAR deployment
-
optional (Aether only): Dependencies considered optional and not required for the execution of the application or plugin
Within the
dependencies block you can specify a dependency that falls into one of these configurations by calling the equivalent method. For example if your application requires the MySQL driver to function at
runtime you can specify that like this:
runtime 'com.mysql:mysql-connector-java:5.1.16'
This uses the string syntax:
group:name:version.
If you are using Aether as the dependency resolution library, the Maven pattern of:
<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version>
You can also use a Map-based syntax:
runtime group: 'com.mysql',
name: 'mysql-connector-java',
version: '5.1.16'Possible settings to the map syntax are:
group - The group / organization (or groupId in Maven terminology)name - The dependency name (or artifactId in Maven terminology)version - The version of the dependencyextension (Aether only) - The file extension of the dependencyclassifier - The dependency classifierbranch (Ivy only) - The branch of the dependencytransitive (Ivy only) - Whether the dependency has transitive dependencies
As you can see from the list above some dependency configuration settings work only in Aether and some only in Ivy.
Multiple dependencies can be specified by passing multiple arguments:
runtime 'com.mysql:mysql-connector-java:5.1.16',
'net.sf.ehcache:ehcache:1.6.1'// Orruntime(
[group:'com.mysql', name:'mysql-connector-java', version:'5.1.16'],
[group:'net.sf.ehcache', name:'ehcache', version:'1.6.1']
)Disabling transitive dependency resolution
By default, Grails will not only get the JARs and plugins that you declare, but it will also get their transitive dependencies. This is usually what you want, but there are occasions where you want a dependency without all its baggage. In such cases, you can disable transitive dependency resolution on a case-by-case basis:
runtime('com.mysql:mysql-connector-java:5.1.16',
'net.sf.ehcache:ehcache:1.6.1') {
transitive = false
}// Or
runtime group:'com.mysql',
name:'mysql-connector-java',
version:'5.1.16',
transitive:falseExcluding specific transitive dependencies
A far more common scenario is where you want the transitive dependencies, but some of them cause issues with your own dependencies or are unnecessary. For example, many Apache projects have 'commons-logging' as a transitive dependency, but it shouldn't be included in a Grails project (we use SLF4J). That's where the
excludes option comes in:
runtime('com.mysql:mysql-connector-java:5.1.16',
'net.sf.ehcache:ehcache:1.6.1') {
excludes "xml-apis", "commons-logging"
}// Or
runtime(group:'com.mysql', name:'mysql-connector-java', version:'5.1.16') {
excludes([ group: 'xml-apis', name: 'xml-apis'],
[ group: 'org.apache.httpcomponents' ],
[ name: 'commons-logging' ])As you can see, you can either exclude dependencies by their artifact ID (also known as a module name) or any combination of group and artifact IDs (if you use the Map notation). You may also come across
exclude as well, but that can only accept a single string or Map:
runtime('com.mysql:mysql-connector-java:5.1.16',
'net.sf.ehcache:ehcache:1.6.1') {
exclude "xml-apis"
}Dependency Management (Aether Only)
If you are using Aether then you can take advantage of Maven's notion of
Dependency Management.
To do so you use a
management block, for example:
management {
dependency "commons-logging:commons-logging:1.1.3"
}The above declaration will force all any transitive dependencies on
commons-logging to use the 1.1.3 version without you having to declare an explicit dependency on
commons-logging yourself. In addition to the version, you can also control the scope and exclusion rules of a dependency.
Where are the JARs?
With all these declarative dependencies, you may wonder where all the JARs end up. They have to go somewhere after all. By default Grails puts them into a directory, called the dependency cache, that resides on your local file system at
user.home/.grails/ivy-cache or
user.home/.m2/repository when using Aether. You can change this either via the
settings.groovy file:
grails.dependency.cache.dir = "${userHome}/.my-dependency-cache"or in the dependency DSL:
grails.project.dependency.resolution = {
…
cacheDir "target/ivy-cache"
…
}The
settings.groovy option applies to all projects, so it's the preferred approach.
5.7.2 Dependency Repositories
Remote Repositories
Initially your BuildConfig.groovy does not use any remote public Maven repositories. There is a default
grailsHome() repository that will locate the JAR files Grails needs from your Grails installation. To use a public repository, specify it in the
repositories block:
repositories {
mavenCentral()
}In this case the default public Maven repository is specified.
You can also specify a specific Maven repository to use by URL:
repositories {
mavenRepo "http://repository.codehaus.org"
}and even give it a name:
repositories {
mavenRepo name: "Codehaus", root: "http://repository.codehaus.org"
}so that you can easily identify it in logs.
Offline Mode
There are times when it is not desirable to connect to any remote repositories (whilst working on the train for example!). In this case you can use the
offline flag to execute Grails commands and Grails will not connect to any remote repositories:
Note that this command will fail if you do not have the necessary dependencies in your local Maven cache
You can also globally configure offline mode by setting
grails.offline.mode to
true in
~/.grails/settings.groovy or in your project's
BuildConfig.groovy file:
To specify your local Maven cache (
~/.m2/repository) as a repository:
repositories {
mavenLocal()
}Authentication with Aether
To authenticate with Aether you can either define the credentials on the repository definition:
mavenRepo(url:"http://localhost:8082/myrepo") {
auth username: "foo", password: "bar"
}Or you can specify an
id on the repository:
mavenRepo(id:'myrepo', url:"http://localhost:8082/myrepo")
And then declare your credentials in
USER_HOME/.grails/settings.groovy:
grails.project.dependency.authentication = {
credentials {
id = "myrepo"
username = "admin"
password = "password"
}
}Authentication with Ivy
If your repository requires authentication you can configure this using a
credentials block:
credentials {
realm = ".."
host = "localhost"
username = "myuser"
password = "mypass"
}This can be placed in your
USER_HOME/.grails/settings.groovy file using the
grails.project.ivy.authentication setting:
grails.project.ivy.authentication = {
credentials {
realm = ".."
host = "localhost"
username = "myuser"
password = "mypass"
}
}5.7.3 Debugging Resolution
If you are having trouble getting a dependency to resolve you can enable more verbose debugging from the underlying engine using the
log method:
// log level of the Aether or Ivy resolver, either 'error', 'warn',
// 'info', 'debug' or 'verbose'
log "warn"
A common issue is that the checksums for a dependency don't match the associated JAR file, and so Ivy rejects the dependency. This helps ensure that the dependencies are valid. But for a variety of reasons some dependencies simply don't have valid checksums in the repositories, even if they are valid JARs. To get round this, you can disable Ivy's dependency checks like so:
grails.project.dependency.resolution = {
…
log "warn"
checksums false
…
}This is a global setting, so only use it if you have to.
5.7.4 Inherited Dependencies
By default every Grails application inherits several framework dependencies. This is done through the line:
Inside the
BuildConfig.groovy file. To exclude specific inherited dependencies you use the
excludes method:
inherits("global") {
excludes "oscache", "ehcache"
}5.7.5 Providing Default Dependencies
Most Grails applications have runtime dependencies on several jar files that are provided by the Grails framework. These include libraries like Spring, Sitemesh, Hibernate etc. When a war file is created, all of these dependencies will be included in it. But, an application may choose to exclude these jar files from the war. This is useful when the jar files will be provided by the container, as would normally be the case if multiple Grails applications are deployed to the same container.
The dependency resolution DSL provides a mechanism to express that all of the default dependencies will be provided by the container. This is done by invoking the
defaultDependenciesProvided method and passing
true as an argument:
grails.project.dependency.resolution = { defaultDependenciesProvided true // all of the default dependencies will
// be "provided" by the container inherits "global" // inherit Grails' default dependencies repositories {
grailsHome()
…
}
dependencies {
…
}
}
defaultDependenciesProvided must come before inherits, otherwise the Grails dependencies will be included in the war.
5.7.6 Snapshots and Other Changing Dependencies
Configuration Changing dependencies
Typically, dependencies are constant. That is, for a given combination of
group,
name and
version the jar (or plugin) that it refers to will never change. The Grails dependency management system uses this fact to cache dependencies in order to avoid having to download them from the source repository each time. Sometimes this is not desirable. For example, many developers use the convention of a
snapshot (i.e. a dependency with a version number ending in “-SNAPSHOT”) that can change from time to time while still retaining the same version number. We call this a "changing dependency".
Whenever you have a changing dependency, Grails will always check the remote repository for a new version. More specifically, when a changing dependency is encountered during dependency resolution its last modified timestamp in the local cache is compared against the last modified timestamp in the dependency repositories. If the version on the remote server is deemed to be newer than the version in the local cache, the new version will be downloaded and used.
Be sure to read the next section on "Dependency Resolution Caching" in addition to this one as it affects changing dependencies.
All dependencies (jars and plugins) with a version number ending in
-SNAPSHOT are
implicitly considered to be changing by Grails. You can also explicitly specify that a dependency is changing by setting the changing flag in the dependency DSL (This is only required for Ivy, Aether does not support the 'changing' flag and treats dependencies that end with -SNAPSHOT as changing):
runtime ('org.my:lib:1.2.3') {
changing = true
}Aether and SNAPSHOT dependencies
The semantics for handling snapshots when using Aether in Grails are the same as those when using the Maven build tool. The default snapshot check policy is to check once a day for a new version of the dependency. This means that if a new snapshot is published during the day to a remote repository you may not see that change unless you manually clear out your local snapshot.
If you wish to change the snapshot update policy you can do so by configuring an
updatePolicy for the repository where the snapshot was resolved from, for example:
repositories {
mavenCentral {
updatePolicy "interval:1"
}
}The above example configures an update policy that checks once a minute for changes. Note that that an
updatePolicy like the above will seriously impact performance of dependency resolution. The possibly configuration values for
updatePolicy are as follows:
never - Never check for new snapshotsalways - Always check for new snapshotsdaily - Check once a day for new snapshots (the default)interval:x - Check once every x minutes for new snapshots
Ivy and Changing dependencies
For those used to Maven snapshot handling, if you use Aether dependency management you can expect the same semantics as Maven. If you choose to use Ivy there is a caveat to the support for changing dependencies that you should be aware of. Ivy will stop looking for newer versions of a dependency once it finds a remote repository that has the dependency.
Consider the following setup:
grails.project.dependency.resolution = {
repositories {
mavenLocal()
mavenRepo "http://my.org/repo"
}
dependencies {
compile "myorg:mylib:1.0-SNAPSHOT"
}In this example we are using the local maven repository and a remote network maven repository. Assuming that the local OI dependency and the local Maven cache do not contain the dependency but the remote repository does, when we perform dependency resolution the following actions will occur:
- maven local repository is searched, dependency not found
- maven network repository is searched, dependency is downloaded to the cache and used
Note that the repositories are checked in the order they are defined in the
BuildConfig.groovy file.
If we perform dependency resolution again without the dependency changing on the remote server, the following will happen:
- maven local repository is searched, dependency not found
- maven network repository is searched, dependency is found to be the same "age" as the version in the cache so will not be updated (i.e. downloaded)
Later on, a new version of
mylib 1.0-SNAPSHOT is published changing the version on the server. The next time we perform dependency resolution, the following will happen:
- maven local repository is searched, dependency not found
- maven network repository is searched, dependency is found to newer than version in the cache so will be updated (i.e. downloaded to the cache)
So far everything is working well.
Now we want to test some local changes to the
mylib library. To do this we build it locally and install it to the local Maven cache (how doesn't particularly matter). The next time we perform a dependency resolution, the following will occur:
- maven local repository is searched, dependency is found to newer than version in the cache so will be updated (i.e. downloaded to the cache)
- maven network repository is NOT searched as we've already found the dependency
This is what we wanted to occur.
Later on, a new version of
mylib 1.0-SNAPSHOT is published changing the version on the server. The next time we perform dependency resolution, the following will happen:
- maven local repository is searched, dependency is found to be the same "age" as the version in the cache so will not be updated (i.e. downloaded)
- maven network repository is NOT searched as we've already found the dependency
This is likely to not be the desired outcome. We are now out of sync with the latest published snapshot and will continue to keep using the version from the local maven repository.
The rule to remember is this: when resolving a dependency, Ivy will stop searching as soon as it finds a repository that has the dependency at the specified version number. It will
not continue searching all repositories trying to find a more recently modified instance.
To remedy this situation (i.e. build against the
newer version of
mylib 1.0-SNAPSHOT in the remote repository), you can either:
- Delete the version from the local maven repository, or
- Reorder the repositories in the
BuildConfig.groovy file
Where possible, prefer deleting the version from the local maven repository. In general, when you have finished building against a locally built SNAPSHOT always try to clear it from the local maven repository.
This changing dependency behaviour is an unmodifiable characteristic of the underlying dependency management system Apache Ivy. It is currently not possible to have Ivy search all repositories to look for newer versions (in terms of modification date) of the same dependency (i.e. the same combination of group, name and version). If you want this behavior consider switching to Aether as the dependency manager.
5.7.7 Dependency Reports
As mentioned in the previous section a Grails application consists of dependencies inherited from the framework, the plugins installed and the application dependencies itself.
To obtain a report of an application's dependencies you can run the
dependency-report command:
By default this will generate reports in the
target/dependency-report directory. You can specify which configuration (scope) you want a report for by passing an argument containing the configuration name:
grails dependency-report runtime
As of Grails 2.3 the
dependency-report command will also output to the console a graph of the dependencies of an application. Example output it shown below:
compile - Dependencies placed on the classpath for compilation (total: 73)
+--- org.codehaus.groovy:groovy-all:2.0.6
+--- org.grails:grails-plugin-codecs:2.3.0
| --- org.grails:grails-web:2.3.0
| --- commons-fileupload:commons-fileupload:1.2.2
| --- xpp3:xpp3_min:1.1.4c
| --- commons-el:commons-el:1.0
| --- opensymphony:sitemesh:2.4
| --- org.springframework:spring-webmvc:3.1.2.RELEASE
| --- commons-codec:commons-codec:1.5
| --- org.slf4j:slf4j-api:1.7.2
+--- org.grails:grails-plugin-controllers:2.3.0
| --- commons-beanutils:commons-beanutils:1.8.3
| --- org.grails:grails-core:2.3.0
...
5.7.8 Plugin JAR Dependencies
Specifying Plugin JAR dependencies
The way in which you specify dependencies for a
plugin is identical to how you specify dependencies in an application. When a plugin is installed into an application the application automatically inherits the dependencies of the plugin.
To define a dependency that is resolved for use with the plugin but not
exported to the application then you can set the
export property of the dependency:
compile('org.spockframework:spock-core:0.5-groovy-1.8') {
export = false
}In this case the Spock dependency will be available only to the plugin and not resolved as an application dependency. Alternatively, if you're using the Map syntax:
compile group: 'org.spockframework', name: 'spock-core',
version: '0.5-groovy-1.8', export: false
You can use exported = false instead of export = false, but we recommend the latter because it's consistent with the Map argument.
Overriding Plugin JAR Dependencies in Your Application
If a plugin is using a JAR which conflicts with another plugin, or an application dependency then you can override how a plugin resolves its dependencies inside an application using exclusions. For example:
plugins {
compile(":hibernate:$grailsVersion") {
excludes "javassist"
}
}dependencies {
runtime "javassist:javassist:3.4.GA"
}In this case the application explicitly declares a dependency on the "hibernate" plugin and specifies an exclusion using the
excludes method, effectively excluding the javassist library as a dependency.
5.7.9 Maven Integration
When using the Grails Maven plugin with the Maven build tool, Grails' dependency resolution mechanics are disabled as it is assumed that you will manage dependencies with Maven's
pom.xml file.
However, if you would like to continue using Grails regular commands like
run-app,
test-app and so on then you can tell Grails' command line to load dependencies from the Maven
pom.xml file instead.
To do so simply add the following line to your
BuildConfig.groovy:
grails.project.dependency.resolution = {
pom true
..
}The line
pom true tells Grails to parse Maven's
pom.xml and load dependencies from there.
5.7.10 Deploying to a Maven Repository
If you use Maven to build your Grails project, you can use the standard Maven targets
mvn install and
mvn deploy.
If not, you can deploy a Grails project or plugin to a Maven repository using the
release plugin.
The plugin provides the ability to publish Grails projects and plugins to local and remote Maven repositories. There are two key additional targets added by the plugin:
- maven-install - Installs a Grails project or plugin into your local Maven cache
- maven-deploy - Deploys a Grails project or plugin to a remote Maven repository
By default this plugin will automatically generate a valid
pom.xml for you unless a
pom.xml is already present in the root of the project, in which case this
pom.xml file will be used.
maven-install
The
maven-install command will install the Grails project or plugin artifact into your local Maven cache:
In the case of plugins, the plugin zip file will be installed, whilst for application the application WAR file will be installed.
maven-deploy
The
maven-deploy command will deploy a Grails project or plugin into a remote Maven repository:
It is assumed that you have specified the necessary
<distributionManagement> configuration within a
pom.xml or that you specify the
id of the remote repository to deploy to:
grails maven-deploy --repository=myRepo
The
repository argument specifies the 'id' for the repository. Configure the details of the repository specified by this 'id' within your
grails-app/conf/BuildConfig.groovy file or in your
$USER_HOME/.grails/settings.groovy file:
grails.project.dependency.distribution = {
localRepository = "/path/to/my/local"
remoteRepository(id: "myRepo", url: "http://myserver/path/to/repo")
}The syntax for configuring remote repositories matches the syntax from the
remoteRepository element in the Ant Maven tasks. For example the following XML:
<remoteRepository id="myRepo" url="scp://localhost/www/repository">
<authentication username="..." privateKey="${user.home}/.ssh/id_dsa"/>
</remoteRepository>Can be expressed as:
remoteRepository(id: "myRepo", url: "scp://localhost/www/repository") {
authentication username: "...", privateKey: "${userHome}/.ssh/id_dsa"
}By default the plugin will try to detect the protocol to use from the URL of the repository (e.g. "http" from "http://.." etc.), however to specify a different protocol you can do:
grails maven-deploy --repository=myRepo --protocol=webdav
The available protocols are:
- http
- scp
- scpexe
- ftp
- webdav
Groups, Artifacts and Versions
Maven defines the notion of a 'groupId', 'artifactId' and a 'version'. This plugin pulls this information from the Grails project conventions or plugin descriptor.
Projects
For applications this plugin will use the Grails application name and version provided by Grails when generating the
pom.xml file. To change the version you can run the
set-version command:
The Maven
groupId will be the same as the project name, unless you specify a different one in Config.groovy:
grails.project.groupId="com.mycompany"
Plugins
With a Grails plugin the
groupId and
version are taken from the following properties in the
GrailsPlugin.groovy descriptor:
String groupId = 'myOrg'
String version = '0.1'
The 'artifactId' is taken from the plugin name. For example if you have a plugin called
FeedsGrailsPlugin the
artifactId will be "feeds". If your plugin does not specify a
groupId then this defaults to "org.grails.plugins".
5.7.11 Plugin Dependencies
You can declaratively specify plugins as dependencies via the dependency DSL instead of using the
install-plugin command:
grails.project.dependency.resolution = {
…
repositories {
…
} plugins {
runtime ':hibernate:1.2.1'
} dependencies {
…
}
…
}If you don't specify a group id the default plugin group id of
org.grails.plugins is used.
Latest Integration
Only the Ivy dependency manager supports the "latest.integration" version. For Aether you can achieve a similar effect with version ranges.
You can specify to use the latest version of a particular plugin by using "latest.integration" as the version number:
plugins {
runtime ':hibernate:latest.integration'
}Integration vs. Release
The "latest.integration" version label will also include resolving snapshot versions. To not include snapshot versions then use the "latest.release" label:
plugins {
runtime ':hibernate:latest.release'
}
The "latest.release" label only works with Maven compatible repositories. If you have a regular SVN-based Grails repository then you should use "latest.integration".
And of course if you use a Maven repository with an alternative group id you can specify a group id:
plugins {
runtime 'mycompany:hibernate:latest.integration'
}Plugin Exclusions
You can control how plugins transitively resolves both plugin and JAR dependencies using exclusions. For example:
plugins {
runtime(':weceem:0.8') {
excludes "searchable"
}
}Here we have defined a dependency on the "weceem" plugin which transitively depends on the "searchable" plugin. By using the
excludes method you can tell Grails
not to transitively install the searchable plugin. You can combine this technique to specify an alternative version of a plugin:
plugins {
runtime(':weceem:0.8') {
excludes "searchable" // excludes most recent version
}
runtime ':searchable:0.5.4' // specifies a fixed searchable version
}You can also completely disable transitive plugin installs, in which case no transitive dependencies will be resolved:
plugins {
runtime(':weceem:0.8') {
transitive = false
}
runtime ':searchable:0.5.4' // specifies a fixed searchable version
}5.7.12 Caching of Dependency Resolution Results
As a performance optimisation, when using Ivy (this does not apply to Aether), Grails does not resolve dependencies for every command invocation. Even with all the necessary dependencies downloaded and cached, resolution may take a second or two. To minimise this cost, Grails caches the result of dependency resolution (i.e. the location on the local file system of all of the declared dependencies, typically inside the dependency cache) and reuses this result for subsequent commands when it can reasonably expect that nothing has changed.
Grails only performs dependency resolution under the following circumstances:
- The project is clean (i.e. fresh checkout or after
grails clean)
- The
BuildConfig.groovy file has changed since the last command was run
- The
--refresh-dependencies command line switch is provided to the command (any command)
- The
refresh-dependencies command is the command being executed
Generally, this strategy works well and you can ignore dependency resolution caching. Every time you change your dependencies (i.e. modify
BuildConfig.groovy) Grails will do the right thing and resolve your new dependencies.
However, when you have
changing or
dynamic dependencies you will have to consider dependency resolution caching.
{info}
A
changing dependency is one whose version number does not change, but its contents do (like a SNAPSHOT). A
dynamic dependency is one that is defined as one of many possible options (like a dependency with a version range, or symbolic version number like
latest.integration).
{info}
Both
changing and
dynamic dependencies are influenced by the environment. With caching active, any changes to the environment are effectively ignored. For example, your project may not automatically fetch the very latest version of a dependency when using
latest.integration. Or if you declare a
SNAPSHOT dependency, you may not automatically get the latest that's available on the server.
To ensure you have the correct version of a
changing or
dynamic dependency in your project, you can:
- clean the project
- run the
refresh-dependencies command
- run any command with the
--refresh-dependencies switch; or
- make a change to
BuildConfig.groovy
If you have your CI builds configured to not perform clean builds, it may be worth adding the
--refresh-dependencies switch to the command you use to build your projects.
